by kirupa |
13 October 2006In the
previous page,
we wrapped up the important things you need to know in order
to use dictionary objects in your projects. In this and the
next page, I will provide some extra information that you
may find useful. You may even impress dinner guests with
your recollection of this material!
After reading these pages, you may be wondering, why you
would need to do all of this to simulate what can easily be
done using Arrays or Lists. Is the added complexity worth
it? The answer to that question is "it depends", but since
this article is about using Dictionaries, I will try to
persuade you on their merits before wrapping up this
tutorial and calling it a day!
Most arrays and lists retrieve information by scanning many
values. If you had to search a list for the existence of a
particular file, you would end up scanning many elements
until you reached the element you are interested in. You may
end up scanning every element, or if your search algorithm
is more efficient, you may search a smaller subset of all
elements.
The following image shows a n-item array/list with a
value somewhere in the middle:
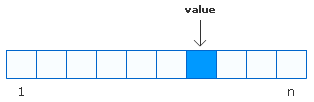
In order to find the cell containing your
value, in the worst case, you have to scan all of the cells
starting at position 1 and ending once you reach the
position of your value. You may use a divide and conquer
approach and find the result logarithmically, but even that
is not the fastest approach. You are wasting computation
cycles in scanning cells that do not contain the value. That
is not the most efficient way of finding information when
you have large amounts of data.
Dictionaries and Hashtables work by finding the exact
location your value is stored and returning that value in
constant time. In other words, no matter how large your
collection of data, you will find an answer in a few steps.
In our linear example, it would take many steps.
Here is a simplified view of how a
dictionary/hashtable represents information:
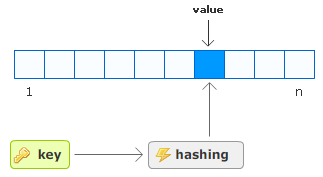
As you have seen from declaring a
Dictionary, when you add a value
to a dictionary, you specify a key also. The key goes
through some kind of transformation called hashing,
and the output of this hashing operation is an index number
of a location in an array-like structure commonly referred
to as a bucket. Your value is added directly to the bucket
referenced by your index number returned by the hash
function.
If you want to retrieve the value, all you
have to do is input the key to your dictionary/hashtable,
and the hashing function returns the index number of the
bucket containing your value. This is done almost
instantaneously. You did not have to scan through
your list at all. You immediately knew, based on the output
of this hashing function, where your data in the list is.
For a given key, your
hash function will always return the same value - the
location of the bucket where your value is stored. This
is what allows you to both store and retrieve the same
value using the same key.
In the above examples, I am assuming that
each bucket contains only one value. In an actual hashtable
implementation, there is a good chance that several values
could be associated with the same key. In the end though,
that doesn't really affect the performance. For given n
items, searching through a handful of them in a bucket
doesn't negatively affect performance. After all, would you
rather scan through five values in a bucket using a
dictionary or about a
hundred values stored in an array?
Onwards to the
next page!
|


